“清华举办的第二届网络传输竞赛,Aitrans2
清华主办的AITrans2。开始入坑的时候没想到这个比赛工作量这么大,特别我还是只有一个人肝的情况下。设计方案,设计算法,基于仿真实现(初赛决赛还是分别基于python和C++的两套系统)的工作量都不小。主要时间也有限,累。赛题地址。
有幸进入最终决赛,决赛的系统有一些功能不支持,导致决赛里方案没有完全实现,最后名次比较靠后,得了一个“最佳个人参赛奖”,答辩效果也很比较一般。感觉这次参赛对自己的结果并不满意。

赛题目标是“时延确定性业务的传输”。核心目标是如何保证尽可能多业务的deadline。赛题分为两个大任务————“发哪个”和“发多快”,即:1.多个数据Block发送顺序的调度策略。2.拥塞控制算法。如图所示:
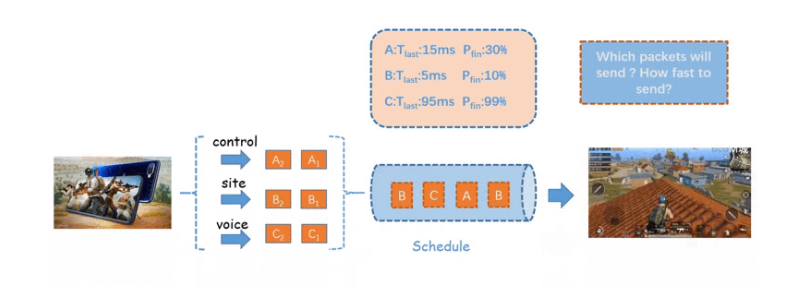
1.Block发送顺序的调度策略
出乎我意料的是,大多数的选手在这个调度策略的选择上大多采用基于规则的策略。原以为会有很多基于AI的策略。
我的策略同样是基于规则的,通过分析QoE得分和不断地线上线下测试调整规则的嵌套逻辑。我的规则大概有10条左右,其中对分数提升最大的有两个rule,分别为Earliest Deadline First调度(即剩余时延最小的block优先被调度)和根据剩余大小分箱策略(对block的剩余大小)进行调度。
EDF调度是比较容易想到的一点,而根据size分箱是基于一个很简单的逻辑,即通过分析QoE的计算规则得出的结论。因为Block的大小差别动辄百倍差别(如一个语音块大小4000B,但一个数据块可能大小十万B),而优先级的大小仅有三种权重(1,2,3)。按照这个逻辑,就算有一个高优先级的Block(3级Block),但它的数据块大小很大的话(十万B),那么它是不应该优先被发送。因为在相同的时间内,我们可以发送50个4000B大小的块。50倍和3倍的差距,我选择50倍。当然,这只是针对在这种QoE规则下的一种策略,毕竟,如何设计QoE本身的规则和公式也是一个玄学。
答辩过程中了解到,95%的选手思路是和我相似的,但还有几只队伍的方案让我觉得印象深刻:1.中科大的队伍通过梯度下降的方式寻找最优的规则组合,这比盲搜显然是一个更有效率的方法。2.另一只队伍将一系列的选block规则转化为一个新的优先级公式,避免了很多if-else的判断。这些都是很有借鉴意义的操作。
2.拥塞控制算法
拥塞控制算法是一个经久不衰的Topic。针对本次比赛对时延敏感业务的需求,选手的方案大致分为两类:传统的方案的和基于深度强化学习的方案。我的方案是基于BBRv1的基本实现。
基于AI的方案,特别是基于深度学习的方案,我其实是不太熟悉的。本次比赛,决赛选手中用到的包括DQN、DDPG、Dualing-DQN、PPO等等。不过在上决赛系统后,不少队伍似乎都出现了问题,导致最后在大网上跑的时候还是用的Baseline的reno算法。
基于深度强化学习的拥塞控制方案似乎近期热度比较高,毕竟拥塞控制本质还是一个控制论的问题。但在答辩中有专家一直在提DQN方案的公平性问题。后续可以好好研究下基于强化学习的拥塞控制相关综述,看看现在AI用在拥塞控制上到底有哪些优势,又有哪些明显需要改进的地方。
而在非AI的方案中,BBR是被选择最多的基础方案(很不幸地又成为大多数),有5-6个队都采用的BBR作为基础算法。大家的想法应该都类似,如果是在时延敏感场景下,基于丢包的拥塞控制机制应该效果不是很好,那么在RTT-based的拥塞控制机制里,BBR应该是近年比较出圈的方案(官方放的参考论文里,第一篇就是BBR)。只是不太理解的是,为什么同为基于BBR的方案,跑分的差距却很大?可能跟具体的工程实现也有很大关系。
除了BBR外,选手们使用的其他的拥塞控制机制,包括COPA,PCC,Fast-TCP等等,也有选手提到了谷歌的Swift。这些拥塞控制机制我都不是特别熟悉(因为之前博士期间主要做二层内容,去到H司后又做了一些三层的东西,对四层的东西仅限于一些科普和PPT)。后续也可以好好研究下相关综述,看看CC今年来都有哪些发展。
3.BBRv1实现踩坑小结
网络上关于BBR原理的资料很多,关于BBR的分析更是多如牛毛。百度上的资料质量参差不齐,它可以帮助你理解,但对于宏观的感觉还是差点意思。这里列举三篇对我帮助比较大的材料:
BBR原始论文: BBR: Congestion-Based Congestion Control
BBRv1 IETF draft:https://tools.ietf.org/html/draft-cardwell-iccrg-bbr-congestion-control-00
论文中有针对BBR的详细介绍,里面有一个巨详细的状态图:https://repository.library.northeastern.edu/files/neu:m044dz373/fulltext.pdf
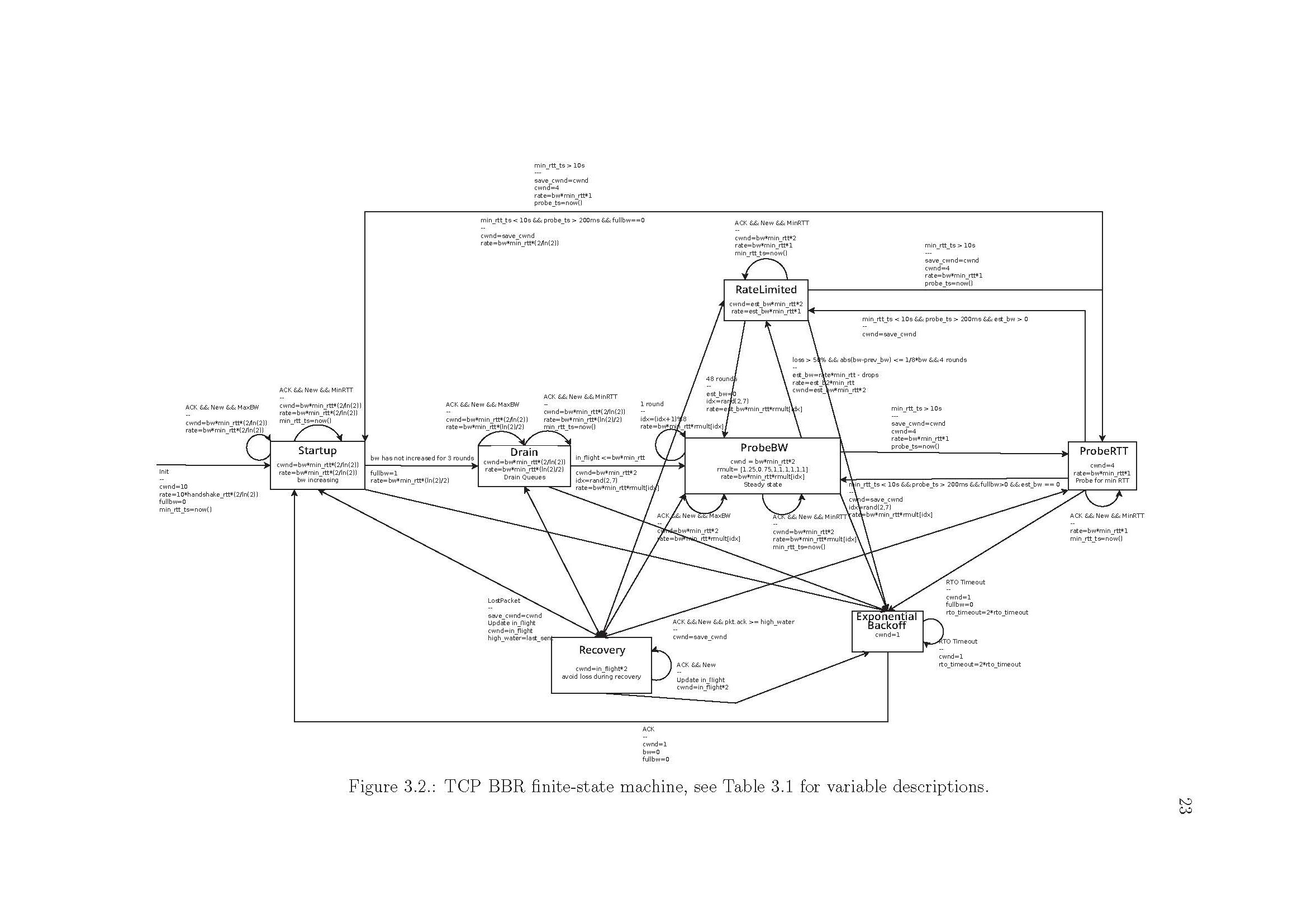
下面用最简单的文字描述下我对BBR的理解:
- 首先,BBR在任何状态下,都用到两个全局变量:即估算带宽和估算链路RTT。当每收到一个ACK时,会更新估算带宽;而当测量RTT超过10s没有发生变化时,则进入更新RTT估算过程。估算的带宽通过delivered_rate计算。
- BBR状态机主要为四个状态:Startup,Drain,ProbeBW,ProbeRTT。
- Startup:该状态类似传统TCP的慢启动,即指数增加窗口(以2/ln2的gain增加cwnd和pacing_rate),以便快速探测当前管道的带宽上限,当估计的带宽增量小于阈值(标准为25%)时,进入Drain状态;
- Drain:该状态中cwnd继续增加,但发送速率开始降低,目的是为了清空队列。理想情况下,队列清空时,BBR工作在最优操作点附近。
- ProbeBW:该状态继续探测是否还有剩余带宽,采用一个循环序列(8个不同的增益参数)调整cwnd。
- ProbeRTT:如果探测到的RTT在一段时间(标准为10s)内都没有减小的话,那么需要重新探测链路RTT,即进入ProbeRTT状态。
在整个实现过程中,困扰我最大的其实是带宽估算过程中,Application limited(rate limited)的问题。即,当发送端没有数据可以发送/或发送断续时,此时的带宽估算值会变成发端的发送速率。此时,带宽增量的降低并不是由于链路利用率过高而导致,而是因为发送速率不够快。此时,BBR会提前进入Drain和ProbeBW阶段,导致带宽浪费严重(?)。关于这个讨论,有一个thread。https://groups.google.com/g/bbr-dev/c/ymEStT_t3LI/m/lUSn0-HKBgAJ
注意到标准中对Applictaion limited状态是有规定的,即如果发现到时Application limited的状态的话,那么会有一个对应的flag标志。携带此标志位的数据包不参与带宽计算。但仿真系统,包括决赛的容器里都没有实现该功能,因此状态切换的阈值就全乱了。后来为了适应这个系统,直接将Startup结束的标志从带宽不再增加,改为RTT增加超过某阈值。这种修改在初赛单流的情况下应该效果非常好,但是在实际场景成千上万条流中实验,效果真的有待检验。
4.总结
这次参赛仍然是抱着学习的心态参加的,毕竟传输层的内容之前并不熟悉,连BBR之前也就知道它是RTT-based的方案,知道它的基本思想。这次终于手把手把它的状态机实现了一遍(仿真平台/实际系统)。而且通过其它小组的方案,了解了这么多传输层相关的知识,感觉还是很有收获的。
知道的越多,才知道自己不知道的越多。这次比赛了解到了自己工程能力还不够强悍,在单枪匹马作战的情况下,到最后也还剩余部分初赛实现的功能没有成功实现在决赛系统上;另一方面,对拥塞控制理论的了解仍然非常欠缺,很多情况下知其然但并不知其所以然,仅仅图快为了工程实现;第三,比赛期间的时间管理能力也存在一些问题,拖延的情况比较严重,纠结方案而没有实际行动,执行力相当欠缺;最后,自己的表达的技能退化得很厉害,这次答辩的PPT内容和现场效果都不太满意,讲话和展示的目的是为了让对方听懂,达到更好交流的目的。
综上,有不同的经历人才会有进步,认识自己的不足才能找到进步的方向,这次比赛的收获非常大。
keep going